
面渣逆袭-Java并发编程
基础
1、并行和并发有什么区别?
- 并行时多核cpu上的多任务处理,多个任务在同一时间真正的同时执行。
- 并发是单核cpu上多任务处理,多个任务在同一时间段内交替执行,通过时间片轮转实现交替执行,用于解决io密集型任务的瓶颈
你是如何理解线程安全的?
如果一段代码被多个线程执行,还能够得到正确的答案,那么这段代码或者方法就是线程安全的。
- 原子性:一个操作要么完全执行,要么完全不执行。(可以使用synchornized保证原子性)
- 可见性:当一个线程修改了共享变量,其他线程能够立即看到变化。(可以使用volatile保证可见性)
- 有序性:要确保线程不会因为死锁、饥饿等问题导致无法继续执行
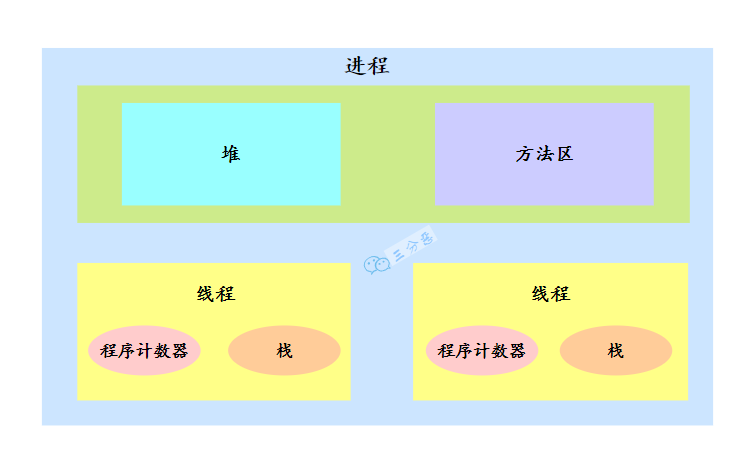
2、说说进程和线程的区别?
进程是操作系统分配资源的最小单位。简单来说,就是我们电脑上启动的一个应用。
线程是进程中的独立执行单元,多个线程可以共享进程中的资源,如内存;每个线程都有自己独立的程序计数器、虚拟机栈。
线程之间是如何进行通信的?
原则上可以通过消息传递和共享内存两种方式来实现。java采用的是共享内存的并发模型。
一句话来概括就是:共享变量存储在主内存中,每个线程的私有本地内存,存储的是这个共享变量的副本。
线程a和线程b要通信,要经历两个步骤:
- 线程a把本地内存A中的共享变量副本刷新到主内存中。
- 线程b到主内存中读取线程a刷新过的共享变量,在同步到自己的共享变量副本中。
⭐️ 3、说说线程有几种创建方式?
创建线程的方式有下面三种:
- 继承Thread,并重写run方法
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(getName() + "线程执行:" + i);
}
}
public static void main(String[] args) {
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
MyThread t3 = new MyThread();
t1.setName("线程1");
t2.setName("线程2");
t3.setName("线程3");
t1.start();
t2.start();
t3.start();
}
}- 实现Runnable接口,并重写run方法
public class MyThreadImpl implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "线程执行:" + i);
}
}
public static void main(String[] args) {
MyThreadImpl t1 = new MyThreadImpl();
MyThreadImpl t2 = new MyThreadImpl();
MyThreadImpl t3 = new MyThreadImpl();
Thread thread1 = new Thread(t1, "线程1");
Thread thread2 = new Thread(t2, "线程2");
Thread thread3 = new Thread(t3, "线程3");
thread1.start();
thread2.start();
thread3.start();
}
}- 实现Callable接口,重写call方法,这种方式可以通过FutureTask获取任务执行的返回值。
public class CallerTask implements Callable<String> {
@Override
public String call() throws Exception {
return "hello world";
}
public static void main(String[] args) {
// 创建异步任务
FutureTask<String> task = new FutureTask<>(new CallerTask());
// 这个任务交给线程来执行,执行完之后任务会有一个返回值。
new Thread(task).start();
try {
// 等待执行完成,并获取返回结果
String result = task.get();
System.out.println(result);
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException(e);
}
}
}run方法和start方法有什么区别?
- run():封装线程执行的代码,直接调用相当于调用普通方法
- start(): 启动线程,然后由jvm调用此线程的run方法。
继承Thread的方式好还是实现Runnable接口好?
Runnable好
- java单继承 的问题
- 适合多个相同的代码去处理统一资源的情况,把线程、代码和数据有效的分离 ,更符合面向对象的设计思想。Callable和Runnable相似,但可以返回一个结果
方法:
- sleep():使当前执行的线程暂停毫秒数,也就是进入休眠的状态
try{
Thread.sleep(1000);
}catch(InterruptedException e){
e.printStackTrace();
}- Join():等待这个线程执行完直呼才会轮到后续线程得到cpu的执行权,使用这个也要捕获异常。
public static void main(String[] args) {
MyThreadImpl t1 = new MyThreadImpl();
// 传入一个实现Runnable的对象
Thread thread = new Thread(t1, "helll");
thread.start();
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 只有当thread执行完之后,才会执行thread1线程
Thread thread1 = new Thread(t1, "hello world");
}- setDaemon: 将此线程标记为守护线程,就是服务其他的线程, 像java中的垃圾回收线程,就是典型的守护线程。
- yield:是一个静态方法,用于暗示当前线程愿意放弃当前的时间片,允许其他线程执行。
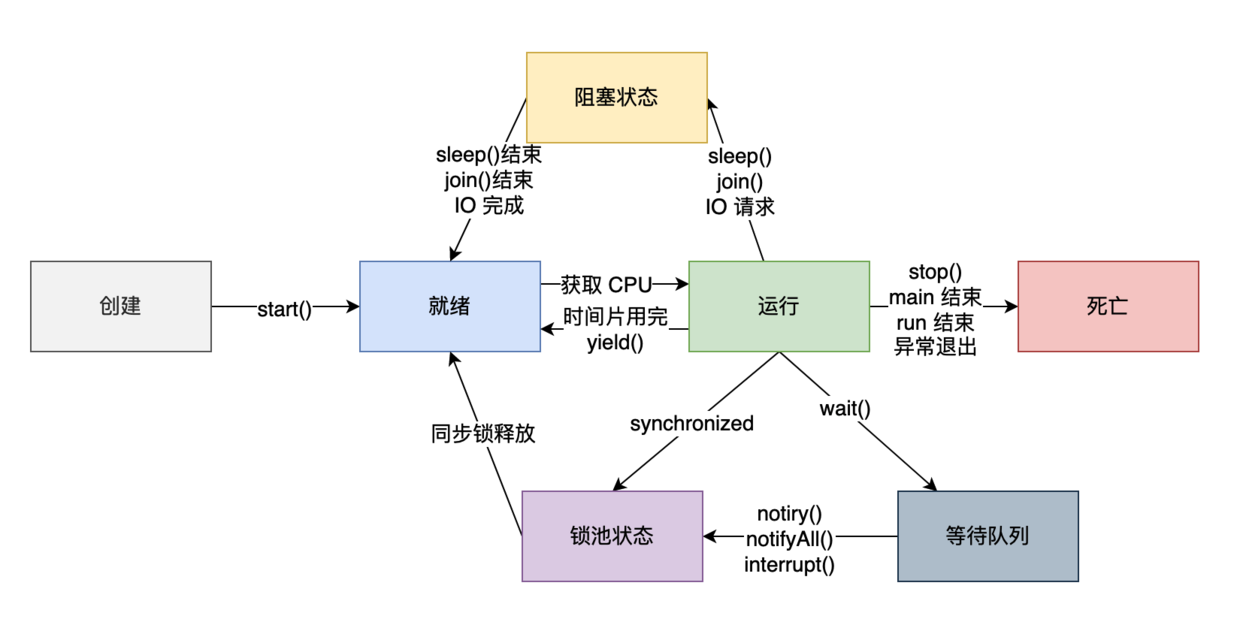
6、线程有几种状态?
6种
新建、就绪、运行、阻塞、等待、终止
- NEW:新建状态,通过new Thread创建
- RUNNABLE:调用start,线程进入可运行状态。
- BLOCKED:
- WAITING:线程进入等待状态,调用wait
- TIME_WAITING:
- TERMINATED:终止状态
推荐阅读
1、synchronized关键字
在java中,关键字synchronized可以保证在同一时刻,只有一个线程可以执行某个方法或者某个代码块,(主要是对方法或者代码块中的共享数据的操作),sycnhronized可以保证一个线程的变化可以被其他线程所看到(保证可见性,完全可以替代volatile功能)
synchronized关键字主要有以下3种应用方式:
- 同步方法,为当前对象(this)加锁,进入同步代码前要获得当前对象的锁
- 同步静态方法,为当前类加锁(锁的是class对象),进入同步代码前要获得当前类的锁
- 同步代码块,指定加锁对象,对给定对象加锁,进入同步代码前要获取到给定对象的锁。
synchronized同步方法
注意:
一个对象只有一把锁,当一个线程获取了该对象的锁之后,其他线程无法获取到该对象的锁,所以无法访问该对象的其他的synchronized方法,但是可以访问其他的非synchronized方法。
每个对象都有一把锁,不同的对象,他们的锁不会相互影响。解决这种问题的方式是将synchronized做用于静态资源上面,这样的话,对象锁的就是类了, 无论创建多少个对象,类只有一个,这种情况下锁就是唯一的。
synchronized同步静态方法
同步静态方法,锁的是类,不影响实例对象锁的获取,两者互相不影响,本质上是this和class的不同。
如果线程a调用一个对象的非静态synchronized方法,线程b调用这个对象所属类的静态synchronized方法,是不会发生互斥的,因为访问静态synchronized方法占用的是class对象,而非静态synchronized方法占用的是当前对象的锁。
synchronized同步代码块
某些情况,我们编写的代码比较多,如果同步方法的话,可能比较耗时,而需要同步的 代码只有一部分。
public class AccountingSync2 implements Runnable {
static AccountingSync2 instance = new AccountingSync2(); // 饿汉单例模式
static int i=0;
@Override
public void run() {
//省略其他耗时操作....
//使用同步代码块对变量i进行同步操作,锁对象为instance
synchronized(instance){
for(int j=0;j<1000000;j++){
i++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(instance);
Thread t2=new Thread(instance);
t1.start();t2.start();
t1.join();t2.join();
System.out.println(i);
}
}我们将synchronized作用与一个给定的实例对象instance上面,就是当前对象就是锁的对象,当线程进入synchronized包裹的代码块是,就要求当前线程有instance对象的锁,如果当前有其他线程在操作的话,那么新的线程就需要等待。
除了instance作为对象外,还可以使用this或者当前类的class作为锁,比如:
//this,当前实例对象锁
synchronized(this){
for(int j=0;j<1000000;j++){
i++;
}
}
//Class对象锁
synchronized(AccountingSync.class){
for(int j=0;j<1000000;j++){
i++;
}
}synchronized属于可重入锁
从互斥的角度来看,一个线程操作另外一个线程持有的对象的锁的临界资源的时候,将会进入阻塞状态;但是一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁,将会请求成功。
synchronized就是可重入锁,因此一个线程在调用synchronized的时候,内部调用该对象的另外一个synchronized方法时允许的。
2、synchronized到底锁的什么?偏向锁、轻量级锁、重量级锁到底是什么?
首先需要明确一点:java多线程的锁都是基于对象的,java中的每一个对象都可以作为一个锁。
还有一点,就是我们常说的类锁其实也是对象锁。(class对象是一种特殊的java对象
锁的基本用法
临界区:指的是某一块代码区域,它同一时刻只能由一个线程执行。
下面这两个写法其实是等价的:
// 关键字在实例方法上,锁为当前实例
public synchronized void instanceLock() {
// code
}
// 关键字在代码块上,锁为括号里面的对象
public void blockLock() {
synchronized (this) {
// code
}
}同理,下面的两个方法也是等价的。
// 关键字在静态方法上,锁为当前Class对象
public static synchronized void classLock() {
// code
}
// 关键字在代码块上,锁为括号里面的对象
public void blockLock() {
synchronized (this.getClass()) {
// code
}
}锁的四种状态及锁降级
jdk1.6及其以后,一个对象其实有四种锁状态,他们级别由低到高分别是:
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态
各种锁的优缺点:(来自《Java并发编程艺术》)
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比,仅存在纳秒级差距 | 如果线程间存在锁竞争会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步快 |
| 轻量级锁 | 竞争的线程不会阻塞,提高程序的响应速度 | 如果始终得不到锁的线程使用自旋会消耗cpu | 追求响应时间 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗cpu | 线程阻塞,响应时间慢 | 追求吞吐量,同步执行时间较长 |
对象的锁放在什么地方
每个java对象都有一个对象头。如果是非数组类型,则用2个字宽存储对象头,如果是数组,则用3个字宽来存储对象头。在32位处理器中,一个字宽32位,在64位虚拟机中,一个字宽64位。
对象头内容如下:
| 长度 | 内容 | 说明 |
|---|---|---|
| 32/64bit | Mark Word | 存储对象的hashcode或者锁信息 |
| 32/64bit | Class Metadata Address | 存储到对象类型数据的指针 |
| 32/64bit | Array Length | 数组的长度(如果是数组) |
可以看到,当对象状态位偏向锁,mark word存储的就是偏向的线程id;当状态为轻量级锁时,mark word存储的就是执行线程中lock record的指针;当状态为重量级锁时,mark word为指向堆中的monitor(监视器)对象的指针。
偏向锁
Hotspot的作者研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一个线程多次获得,于是便引入了偏向锁。
偏向锁的实现原理。
一个线程在第一次进入同步快时,会在对象头和栈帧中的锁记录里面存储锁偏向的线程id,当下次该线程进入 这个同步块时,会去检查锁的mark word里面是不是自己放的线程id。
如果是,表明线程已经获得了锁,以后该线程在进入和退出同步块时不需要花费cas操作来加锁和解锁;如果不是,就代表有另外一个线程来竞争这个偏向锁。这个时候会尝试使用cas来替换mark word里面的线程id为心线程的id,这个时候要分两种情况:
- 成功,表示之前的线程不存在了,mark word 里面的线程id为心线程的id,锁不会升级,仍然为偏向锁。
- 失败,表示之前的线程仍然存在,那么暂停之前的线程,设置偏向锁表示为0,并设置锁标志为00,升级为轻量级锁,会按照轻量级锁的方式竞争锁。
撤销偏向锁
偏向锁使用一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会什邡锁。
偏向锁升级成轻量级锁时,会暂停通邮偏向锁的线程,重置偏向锁表示,看起来容易,实则开销还是很大。
轻量级锁
多个线程在不同时段获取同一把锁,即不存在锁竞争的情况,也就没有线程阻塞,正对这种情况,jvm采用轻量级锁来避免线程的阻塞于唤醒。
获取轻量级锁的过程,jvm会为每个先哼在当前线程的栈帧中创建用于存储锁记录的空间,我们称为di splaced mark word, 如果一个线程获得锁的时候发现是轻量级锁,会吧锁的mark word复制到自己的displaced mark word 里面。
然后线程尝试使用cas将锁的mark word替换为指向锁记录的指针,如果成功,或得锁,如果失败,会自旋,不断尝试去获取锁,自旋量费cpu资源,解决这个问题就是指定自旋的次数,例如10次,如果还没有获取到,就进入阻塞状态,jdk采用更聪明的方法,适应性自旋,简单来说就是线程如果自旋成功了,那么下次自旋的次数会更多,失败了,下次则减少。
自旋不会一直进行下去,如果到一定程度还没有获取到锁,自旋失败,线程进入阻塞状态,同时锁升级为重量级锁。
重量级锁
重量级锁依赖于操作系统,而操作系统中线程间装替啊的转换需要相对较长的时间,所以重量级锁效率很低,单被阻塞的线程不会消耗cpu。
3、乐观锁CAS
如何保证原子性呢?
常见的做法就是加锁。
在java中,我们可以使用synchronized关键字和CAS来实现加锁的效果。
synchironized是悲观锁,随着jdk版本的升级,synchronized关键字已经轻量化了许多,但是依然是悲观锁。
悲观锁:总是认为每次访问共享资源时会发生冲突,所以必须对每次数据操作加上锁,以保证临界区的程序同一时间只能有一个线程执行。
乐观锁:假设对共享资源的访问没有冲突,线程可以不停的执行,无需加锁也无需等待,一旦多个线程发生冲突,乐观锁通常使用一种称为CAS的技术来保证线程执行的安全性。(乐观锁天生免疫死锁)
- 乐观锁用于读多写少的环境,避免频繁加锁影响性能
- 悲观锁多用于写多读少的环境,避免频繁失败和重试影响性能。
什么是CAS?
- v:要更新的变量
- e:预期值
- n:新值
判断v是否等于e,如果等于e,就将v修改成n,否则的话,什么都不做。
CAS是原子操作,他是一种系统源语,是一条CPU的原子指令,从cpu层面保证了它的原子性。
当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
CAS的原理?
Unsafe类,里面是一些native的方法,不同的操作系统,实现CAS的原理是不一样的。
CAS如何实现原子操作?
java.util.concurrent.atomic包里面有一些原子类,像是AtomicInteger、AtomicLong等等。
CAS的三大问题?
尽管CAS提供了一种有效的手段,但是也存在一些问题,比如ABA问题、长时间自旋、多个共享变量的原子操作。
- ABA问题:就是一个值原来是A,变成了B,又变回了A,这个时候用CAS是检查不出来变化的,但实际上却被更新了两次。解决思路是在变量前面追加上版本号或者时间戳。
- 长时间自旋:CAS多于自旋结合,如果自旋CAS长时间不成功,会占用大量的cpu资源。(解决思路是让jvm支持处理器提供的pause指令),pause指令能够让自旋失败时,cpu睡眠一小段时间在继续自旋,从而使读操作频率降低,为解决内存顺序冲突而导致的cpu流水线重拍的代价小一点。
- 多个共享变量的原子操作:一个共享变量CAS能保证原子性,但是多个共享变量CAS就无法保证原子性了,通常有两种方法解决,1使用AtomicReference类保证对象之间的原子性,把多个变量放到一个对象里面进行CAS操作;2使用锁,锁内部的临界区代码可以保证只有当前线程能操作。
4、线程池
什么是线程池
线程池是一种池化技术实现,池化技术的核心就是实现资源的复用,避免资源的重复创建和销毁带来的额外的开销。线程池可以管理一堆线程,让线程执行完任务之后不进行销毁,而是继续去处理其他线程已经提交的任务。
使用线程池的好处
- 降低资源消耗,避免线程重复创建、销毁浪费资源
- 提高响应时间,任务可以不用等待线程的创建就能执行。
- 提高线程可管理性,线程是稀缺资源,如果无限创建,不仅会消耗系统资源,还会降低系统的稳定性。
线程池的构造
java主要通过构建ThreadPoolExecutor来创建线程池的。
下面是线程池的java源码
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}我们可以看到有六个参数,下面分别来说一下不同的参数的含义:
- corePollSize:线程池中用来工作的核心线程数量。
- maximumPoolSize:最大线程数,线程池允许创建的最大的线程数。
- keepAliveTime:超出corePoolSize后创建的线程存活时间或者是所有线程最大存活时间,取决于配置。
- unit:keepAliveTime的时间单位
- workQueue:任务队列,是一个阻塞队列,当线程数大道核心线程数后,会将任务存储到阻塞队列中
- threadFactory:线程池内部创建线程所用的工厂
- handler:拒绝策略,当队列已满并且线程数量达到最大线程数量时,会调用该方法处理任务。
线程池的运行原理
线程池刚创建出来是空的,是没有线程的,只有一个空的阻塞队列。可以使用prestartAllCoreThreads方法来实现创建好核心线程。
当线程调用execute方法提交一个任务,会发生什么?
首先判断当前线程数是否小于核心线程,如果小于的话,那就使用threadFactory创建线程,否则的线程就执行任务,线程执行完任务之后,不会销毁,会继续在阻塞队列里面找任务执行。
这里有个细节,就是线程从阻塞队列里面没有获取到任务,如果线程数小于核心线程数,还是会去创建线程 ,不会复用已有的线程。
任务来了之后,会先到阻塞队列中,当阻塞队列满了之后会发生什么?
此时会判断线程池里面的线程数是否小于最大线程数,如果小于就创建线程,这里创建出来的是非核心线程,就算队列里面有任务,新创建的线程还是会线程处理这个提交的任务,而不是从队列里面获取。从这里可以看出,先提交的任务不一定先执行。
假如线程数已经达到了最大线程数,会怎么办?
这个时候就会执行拒绝策略,来处理任务。
jdk自带的实现RejectedExecutionHander有四种
- AbortPolicy;丢弃任务,抛出运行时异常
- CallerRunsPolicy:由提交任务的线程来执行任务
- DiscardPolicy:丢弃任务,但是不抛异常
- DiscardOldestPolicy:从队列中剔除最先进入队列的任务,然后在此提交任务。
- 自定义的实现了RejectedExecutionHandler接口的类,可以将任务存到数据库或者缓存中。
线程池中实现线程复用的原理
就是runWork内部,使用了一个while死循环,当第一个任务执行完之后,会不断的通过getTask来获取任务,只要能获取到任务,就会调用run方法执行,如果获取 不到任务,就会调用processWorkerExit方法,将线程退出。
如何获取任务执行超时的
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();就是从队列里面获取任务的时候传入了超时时间,如果在这个时间段都没有获取到任务,那么 结束之后线程也没了。
Executors构建线程池以及问题分析
- 固定线程数的线程池,核心线程数和最大线程数相等。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}- 单个线程数量的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}- 接近无限大线程数量的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}但是不推荐使用Executors来创建线程池。
Changelog
4c155-on