
面渣逆袭-Java集合框架
引言
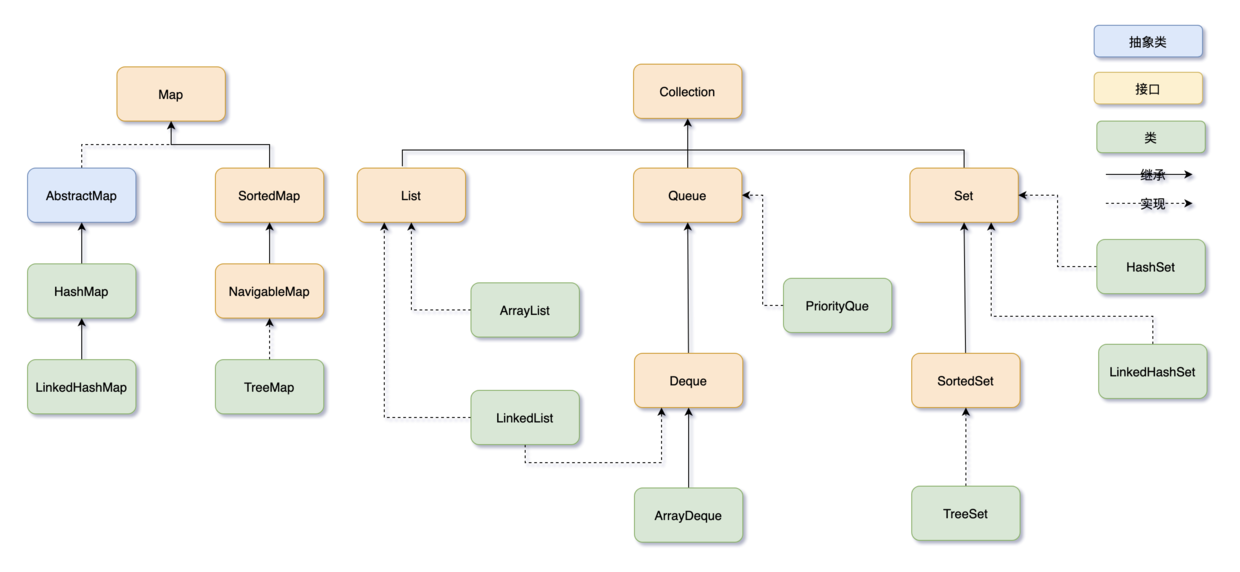
1、说说有哪些常见的集合框架?
- 推荐阅读:二哥的 Java 进阶之路:Java 集合框架
- 推荐阅读:阻塞队列 BlockingQueue。
2、ArrayList和LinkedList有什么区别?
底层实现的数据结构不同。
他两个特点,ArrayList利于查询, LinkedList利于增删
Map
8、能说一下HashMap的底层数据结构吗?
JDK8中,HashMap的数据结构是: 数组+链表+红黑树
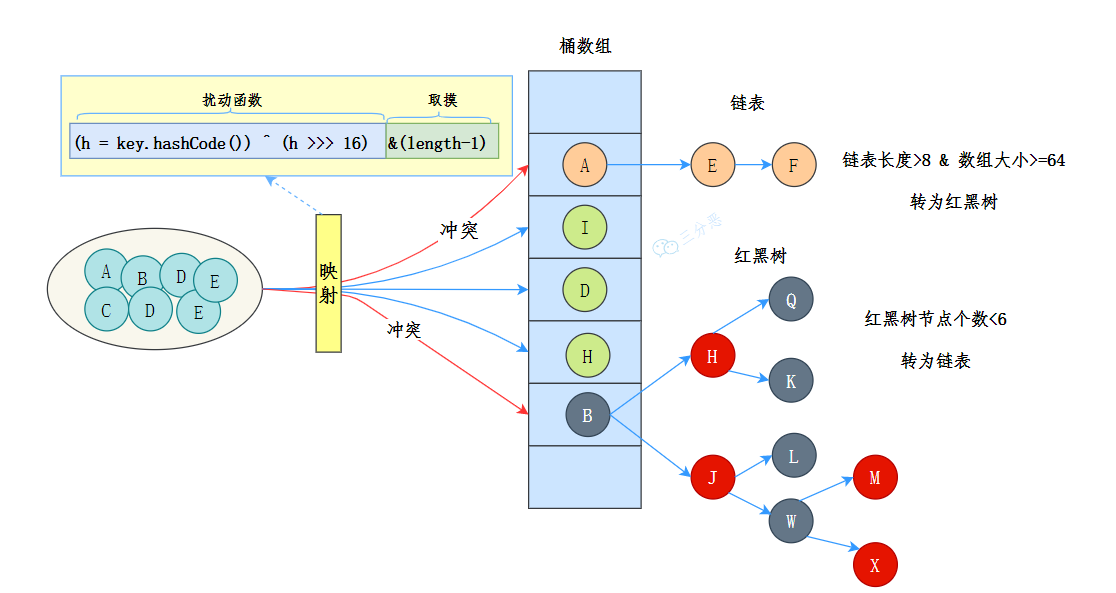
数组用来存储键值对,每个键值对可以通过索引直接拿到,索引是通过对键的哈希值进行进一步的hash()处理得到的。
当多个键经过哈希处理后得到相同的索引时,需要通过链表来解决哈希冲突-将具有相同索引的键值对通过链表存储起来。
不过,链表过长时,查询效率会比较低,于是当链表长度超过8(且数组的长度大于64),链表就会转化成红黑树,红黑树的查询效率是O(logn),比链表的O(n)要快。
HashMap的初始容量是16,map扩容,阈值capacity * loadFactor, capacity为容量,loadFactor为负载因子,默认是0.75,扩容的数组大小是原来的2倍,然后把原来的元素重新计算哈希值,放到新的数组里面。
9、你对红黑树了解多少?
红黑树是一种自平衡的二叉搜索树。
1.每个节点要么是红色,要么是黑色
2.根节点永远是黑色。
3.所有的叶子节点都是黑色的(图中的null节点)。
4.红色节点的子节点一定是黑色的
5.从任意节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
为什么不用二叉树?
二叉树是最基本的树结构,每个节点最多有两个子节点,但是二叉树容易出现极端情况,就是插入有序的数据,那么二叉树就会退化成链表,查询效率变成O(n).
为什么不用平衡二叉树?
平衡二叉树比红黑树的要求更高,每个节点的左右子树的高度最多相差1,这种高度的平衡保证了极佳的查询效率,但在进行插入和删除操作时,可能需要频繁的进行旋转来维持树的平衡,维护成本更高。
为什么用红黑树?
链表的查询时间复杂度时O(n),当链表长度较长时,查询效率就会下降,红黑树是一种折中的方案,查找、插入、删除的时间复杂度都是O(logn).
10、红黑树如何保持平衡的?
- 通过左旋和右旋来调整树的结构,避免某一侧过深。
- 染色,修复红黑树规则, 从而保证树的高度不会失衡。
Changelog
4c155-on