
初始领域驱动设计(Domain Driver Design)
领域驱动设计(DDD)是一种应对复杂软件系统开发的核心方法。它强调通过构建精确的领域模型和通用语言作为核心,聚焦业务领域复杂性,实现业务逻辑与技术实现的紧密贴合与统一演进。
一、DDD入门
@Transactional//事务边界
public void updateMyMobile(String mobileNumber, String memberId) {
//采用事务脚本的方式,直接通过SQL语句实现业务逻辑
String sql = "update member set mobile_number = ? , mobile_identified = 1 where id = ?;";
jdbcTemplate.update(sql, mobileNumber,memberId);
}存在问题,业务代码和技术代码揉杂在一起。
面向对象编程OOP。
@Transactional
public void updateMyMobile(String mobileNumber) {
String memberId = CurrentUserContext.getCurrentMemberId();
Member member = memberRepository.findMemberById(memberId);
//先后调用Member对象中的2个setter方法实现业务逻辑
member.setMobileNumber(mobileNumber);
member.setMobileIdentified(true);
memberRepository.updateMember(member);
}电话号码用户能改,管理员也能改的话,这样就需要多处进行修改,定义多个方法。(贫学模型)
领域对象。
@Transactional
public void updateMyMobile(String mobileNumber) {
String memberId = CurrentUserContext.getCurrentMemberId();
Member member = memberRepository.findMemberById(memberId);
//只需调用Member种的updateMobile()方法即可
member.updateMobile(mobileNumber);
memberRepository.updateMember(member);
}更新的具体操作交给领域对象来做,比如这里的updateMobile。
//由Member对象自身处理同时更新mobileNumber和mobileIdentified字段
public void updateMobile(String mobileNumber) {
this.mobileNumber = mobileNumber;
this.mobileIdentified = true;
}在DDD中Member对象被称为 聚合根,而更新mobileNumber的同时需要一并更新mobileIdentified则被称为聚合根的不变条件。
(坚持代码即是设计的原则,让代码本身直接体现业务意图)。
MerberDomainService为领域服务,用于处理领域对象自身无法处理的业务逻辑。

- 《领域驱动设计:软件核心复杂性应对之道》(蓝皮书,从左往右第一本,首版时间2003年):DDD的开山之作,对于初学者来说阅读起来有些晦涩,不建议初学者直接阅读该书
- 《实现领域驱动设计》(红皮书,从左往右第二本,首版时间2013年):这本是讲DDD落地的经典书籍,其中包含大量代码示例,很多人都是通过这本书才真正进入DDD的世界
- 《领域驱动设计模式、原理与实践》(从左往右第三本,首版时间2015年):这也是一本能够帮你系统的完成DDD落地的书籍
- 《解构领域驱动设计》(首版时间2021年):国内第一本关于DDD的专著,作者张逸在DDD社区具有比较大的影响力
二、DDD概念大白话
产品代码都给你看了,可别再说不会DDD(二):DDD概念大白话
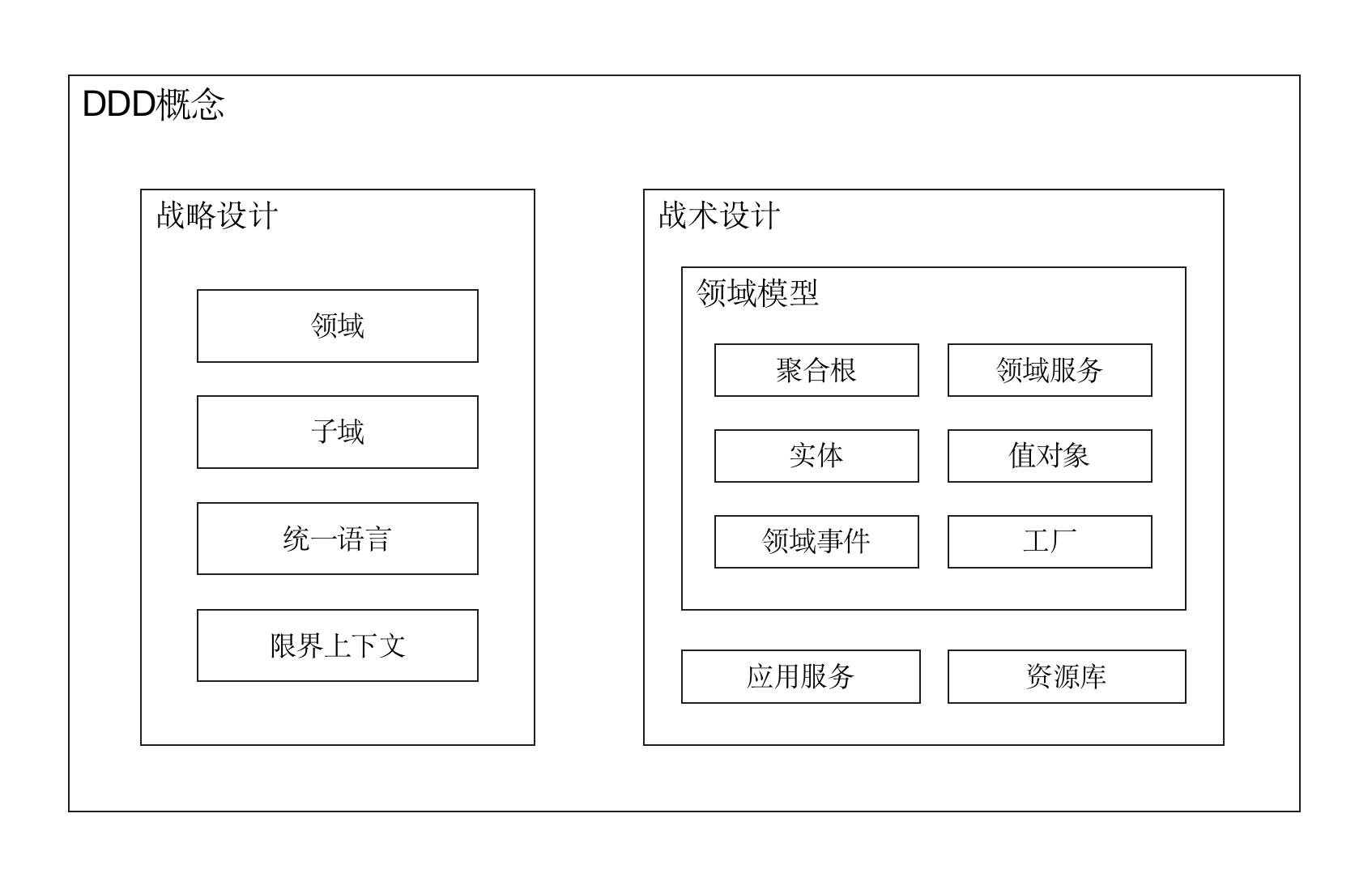
聚合根:
- 聚合根属于实体,但是实体不一定是聚合根
领域服务:
- 领域服务是领域模型的一部分
实体:用于表示那些具有生命周期的“存在”,实体通过唯一标识进行标定,实体有ID
值对象:用于表示那些仅仅起描述性作用的东西,值对象则通过其包含的所有属性进行标定,值对象没有ID
领域事件:
- 一个业务操作通常会导致一个结果,这个结果被称为领域事件,即领域模型中已经发生的事情。
- 领域事件通常用于组建之间的因果关系处理,比如:当成员手机号已更新事件产生后,我们可能会在另一个业务组件中做相应的同步操作,这里的组件粒度可以是聚合根,可以是其他业务模块,还可以是一个独立的第三方系统。
资源库(Repository):
- 用于保存/获取聚合根。DAO对象用于存储对象,但是与DAO不同的是,资源库操作的基本单位是聚合根,也即只有聚合根对象才配得上拥有资源库,其他实体对象则没有
应用服务:
- 领域模型是用来完成业务功能的,也即需要效应用户发起的各种请求,但是在软件系统中在这些请求达到领域模型之前,事实上还有很多事情需要处理,比如需要从数据库中加载数据(聚合根)、处理事务、权限管控等,在DDD中,这些操作由应用服务(Application Service)完成。应用服务可以看作领域模型的门面,它将接收到的请求派发给合适的领域模型去处理,在整个过程中,应用服务充当的是协调者和编排者的角色,就像酒店的前台一样。
如果成功没有如期而至,那只是因为我们没有付出足够的努力。
当你遇到任何问题,记住,解决问题的办法永远在问题之外。
成功只会眷顾那些持之以恒、竭尽全力,并能够战胜挑战的人。
三、战略设计
DDD的战略设计只在解决一个问题,就是软件的模块划分的问题。
战略设计中包含领域、子域、通用语言和限界上下文等概念。
领域(Domain)表示一个行业中所发生的一切业务;
子域(Subdomain)表示领域中细分之后的子业务,是比领域更小的概念,子域可以细分为核心子域、支撑子域、和通用子域;
通用语言(Ubiquitous Language):表示领域中所有人员都是用一套相同的语言进行沟通交流 ;
限界上下文(Bounded Context):表示由通用语言形成的上下文边界。
核心域 - 电商系统中的订单系统;支撑域-积分模块;通用域-登录模块。限界上下文:交易模块中的订单和物流模块中的订单,不同的语境表示不同的含义。
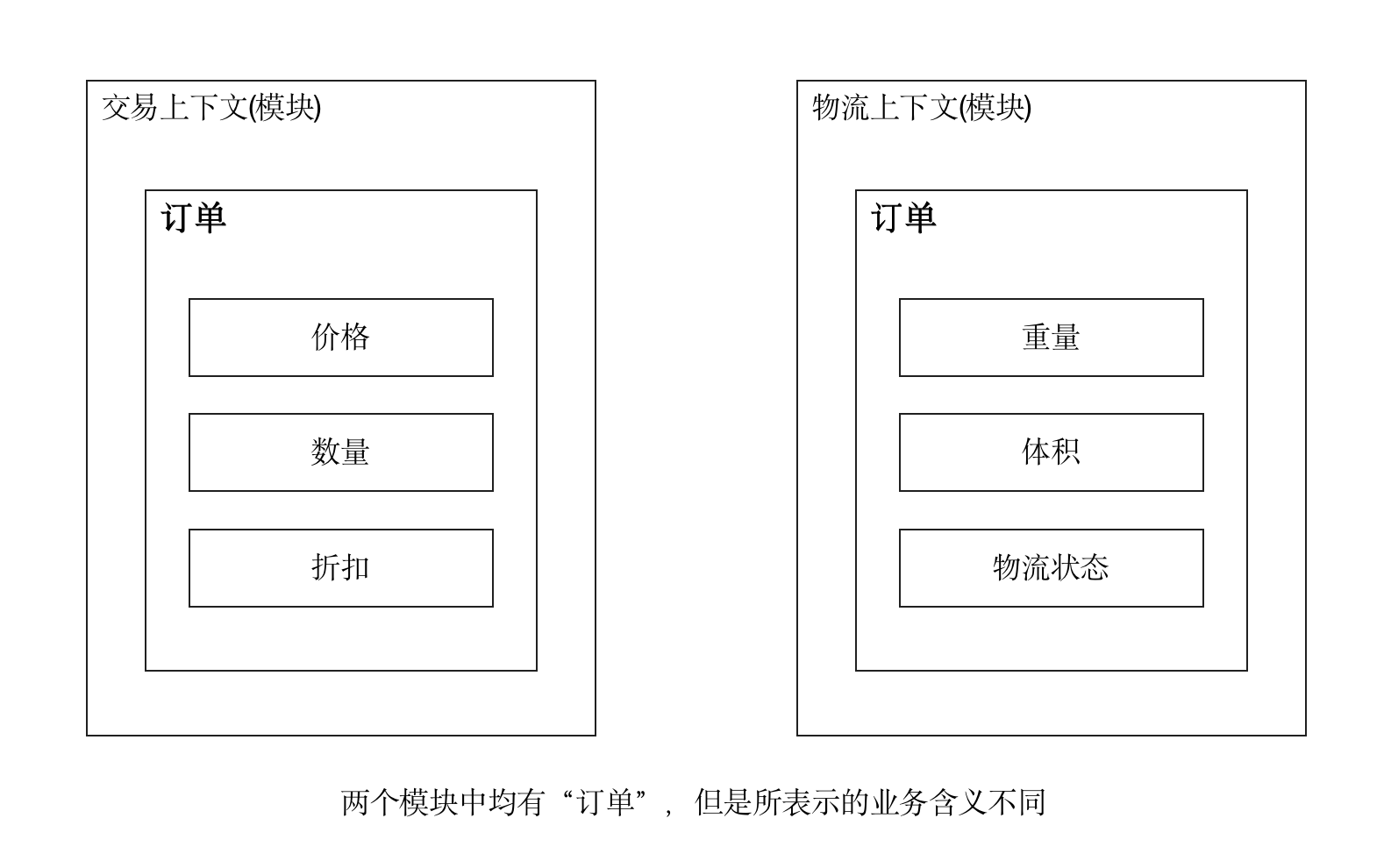
软件设计中模块的概念。
难点不在于如何定义模块,而是在于如何划分模块。
“我通过自己对业务的深入了解,外加自己的从业 经验和抽象能力,搞定了DDD的战略设计”。
“知识归根到底由经验而来 -- 约翰 洛克”
“知识的唯一来源是经验 -- 爱因斯坦”
什么是架构?一种解释是:软件架构是项目中的资深程序员们对某个问题所达成的统一认识而已。
码如云模块划分:
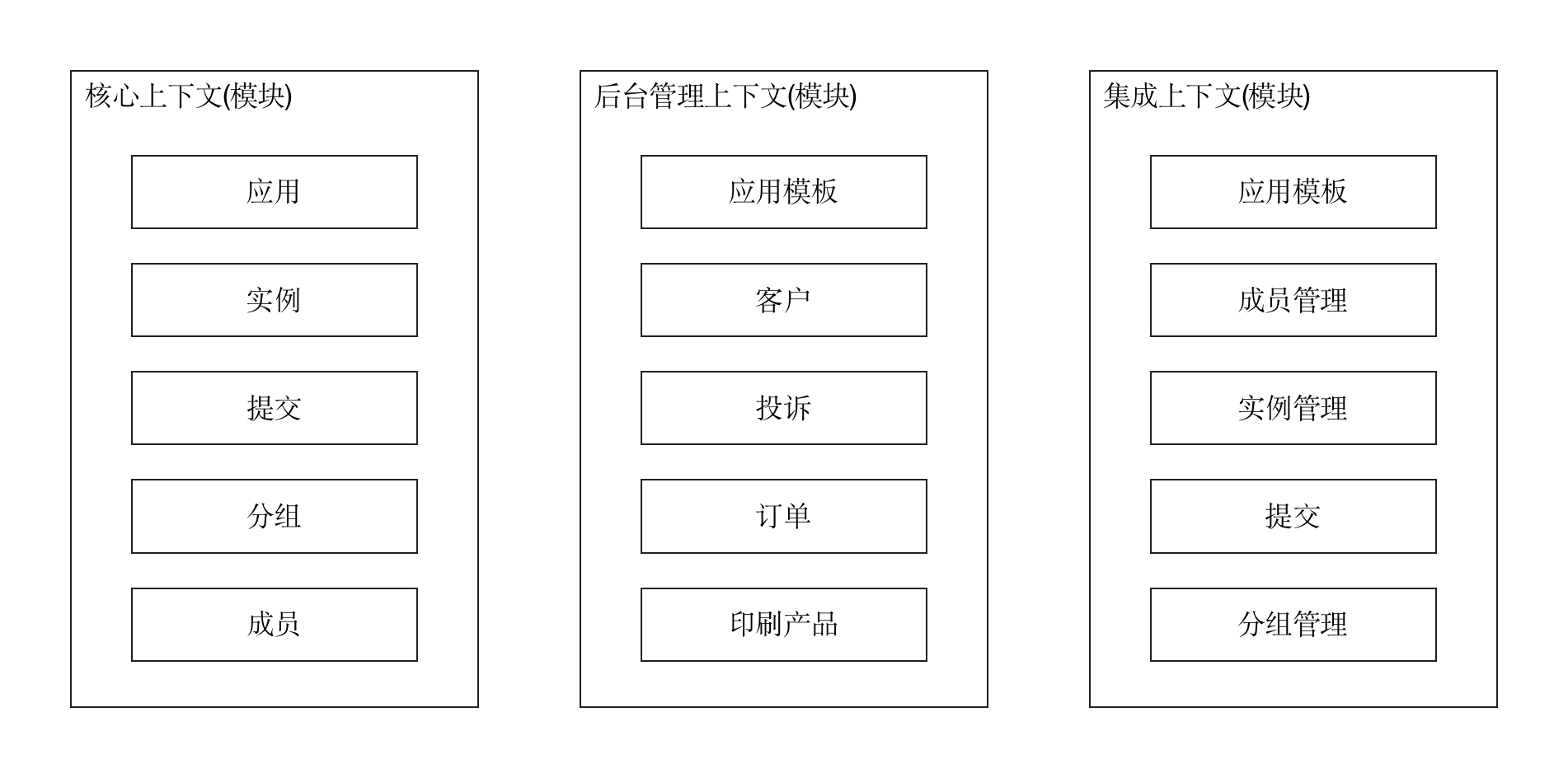
三个顶层模块,一个是核心上下文(模块),其中包含各种核心的业务实体,比如应用和实力等,每个月业务实体均被建模为一个聚合根;第二个是后台管理上下文(模块),用于码如云的后台运营,包含客户关系、投诉管理和订单管理;第三个是集成上下文(模块),用于处理与第三方的API集成。
在前文提到,登录功能可以看作是通用子域而模块为一个独立的模块,但是码如云中并未这样划分,而是将登录功能消化在核心上下文中,因为其粒度尚未达到需要独立为一个模块的程度。
总结:
这一章的话,介绍了一些概念,像是领域、子域、限界上下文,然后对这些概念进行了举例说明,然后聊到模块化的重要性。
总的来说就是,DDD就是来划分模块的,不是贬低,而是让我们了解到战略设计的本质。
那战略设计的本质是什么?
开头说了,战略设计的本质只解决一个问题,就是软件的模块划分问题(就是如何划分模块)。
四、代码工程结构

将技术分包作为顶层分包是一种反模式。

DDD建议分包时:“先业务,后技术。”
好处:
- 业务直观
- 便于导航。当找一个功能的时候,首先想到的是该功能属于哪个业务模块,而不是属于哪个Controller。
- 便于迁移。每个业务包都包含了从业务到技术的所有代码,因此在迁移时只需要整体挪动业务包即可。
domain包代码量远超其他所有分包,强调在DDD中领域模型应该是代码的主体。
总结:
本章的话,主要讲述了码如云项目的代码架构,以先业务后技术的方式来组织代码。
五、请求处理流程
DDD中所有的组件都是围绕着聚合根展开的,其中有些本身就是聚合根的一部分,比如实体和值对象;有些是聚合根客户,比如应用服务;有些则是对聚合根的辅助或补充,比如领域服务和工厂。
反观当前流行的各种软件架构,无论是分层架构还是整洁架构,他们都有一个共同点,即在架构中心都有一个核心存在,这个核心正是领域模型,而DDD的聚合根则存在于领域模型之中。
“以领域模型为中心的软件架构。”
DDD项目如何衔接外部请求和内部领域模型的?
- 聚合根创建、更新、删除流程,查询流程, 4个流程。
聚合根创建流程
创建通过工厂类完成,流程路线:控制器Controller -> 应用服务Application Service -> 工厂Factory -> 资源库Repository
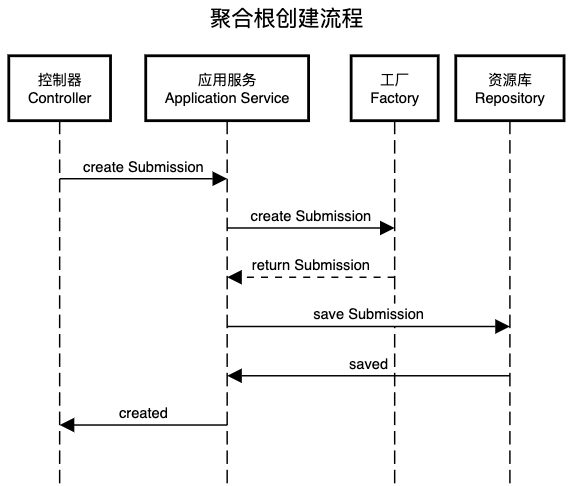
Controller的作用只是为了衔接技术和业务,因此其逻辑应该相对简单。
处理流程的下一站是应用服务,应用服务是整个领域模型的门面,无论什么类型的客户端,只要业务用例相同,那么所调用的应用服务的方法也应相同,也即应用服务和技术设施也是解藕的。
可见,应用服务主要用于协调各方以完成一个业务用例,其本身不包含业务逻辑,业务逻辑在工厂中完成(submissionFactory.createNewSubmission())。
聚合根更新流程
三部曲:
- 1 调用资源库获取到聚合根
- 2 调用聚合根上的业务方法,完成对聚合根的更新
- 3 再次调用资源库保存聚合根
流程:控制器Controller -> 应用服务Application Service -> 资源库Repository -> 聚合根Aggregate Root
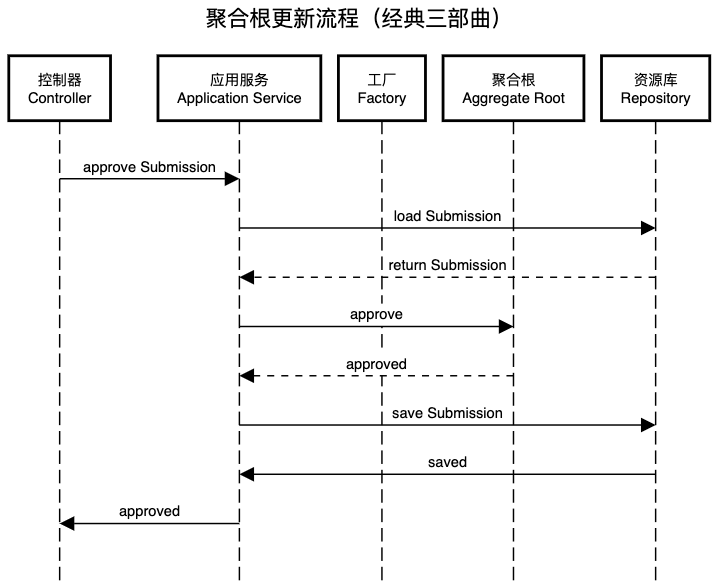
submissions.approve()是领域对象中的方法。
不是所有的业务用例都适合“经典三部曲”,有时聚合根自身无法完成所有的业务逻辑,此时我们则需要借助领域服务Domain Service来完成请求的处理。比如常见的领域服务的场景需要进行跨聚合查询的时候。此时的 请求路径是:控制器Controller -> 应用服务Application Service -> 资源库Repository -> 聚合根Aggregate Root -> 领域服务Domain Service
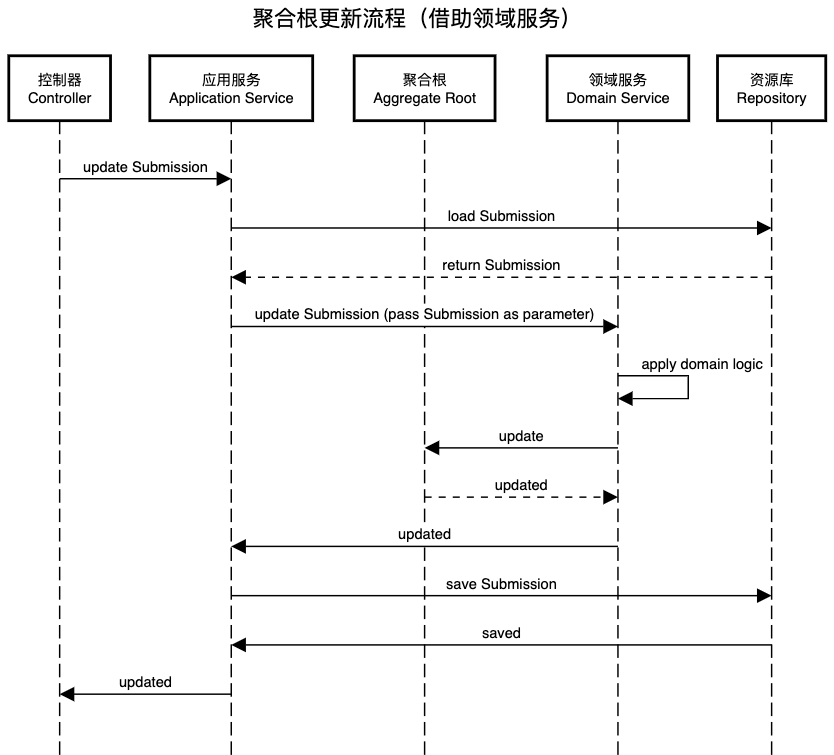
领域服务SubmissionDomainService.updateSubmission()首先调用业务方法checkAnswers()对表单内容进行检查,在调用Submission.update完成对Submission的更新,相当于领域服务对聚合根作业业务上的加工,并不负责持久化Submission,持久化的职责依然在应用服务上,这样的好处是:与“经典三部曲”保持一致,将所有持久化操作均集中到应用服务中,不至于过于分散;使领域服务的职责尽量单一。
聚合根的删除流程
相对简单,流程路径:控制器Controller -> 应用服务Application Service -> 资源库Repository -> 聚合根Aggregate Root
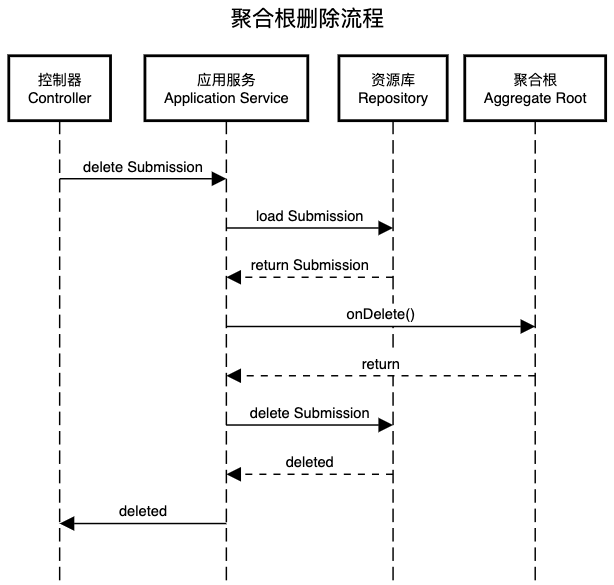
Submission.onDelete()以完成删除前的一些操作,在本例中onDelete将发出“提交一删除(SubmissionDeletedEvent)领域事件” ,然后Repostory.delete()完成对聚合根的删除操作。
查询流程
在本系列的CQRS一文中,将专门讲到DDD的查询操作。
总结
将了一些操作流程,比如聚合根的新增、更新、删除操作,以聚合根为中心,围绕形成恰如其分的软件架构。
六、聚合根与资源库
领域模型是DDD的核心,而聚合根又是领域模型的核心。从某种意义上来说,DDD的其他组件是对聚合根的支撑和辅助。下面讨论聚合根与资源库的关系。
聚合根是什么
聚合根中的聚合即“高内聚,低耦合”中的内聚之意,根表示根部的意思,也即聚合根是一种统领式的存在。
举例:
- 在一个电商系统中,一个订单Order对象表示一个聚合根
- 在银行系统中,一次交易Transaction对象表示一个聚合根
为什么会有聚合根的概念?
1、聚合根遵循了软件中“高内聚,低耦合”的基本原则。
2、聚合根体现了一种模块化的原则,模块化思想是被各个行业所证明的可以降低系统复杂度的一种思想。所谓DDD是“软件核心复杂性应对之道”,也是这个意思,它将软件系统在人脑中所呈现的更加有序和简单,让人可以更好的理解和管控软件系统。
聚合根基类
//AggregateRoot
@Getter
public abstract class AggregateRoot implements Identified {
private String id;//聚合根ID
private String tenantId;//租户ID
private Instant createdAt;//创建时间
private String createdBy;//创建人的MemberId
private String creator;//创建人姓名
private Instant updatedAt;//更新时间
private String updatedBy;//更新人MemberId
private String updater;//更新人姓名
private List<DomainEvent> events;//临时存放领域事件
private LinkedList<OpsLog> opsLogs;//操作日志
@Version
@Getter(PRIVATE)
private Long _version;//版本号,实现乐观锁
//...此处省略了AggregateRoot中行为方法
@Override
public String getIdentifier() {
return id;
}
}基类的一些字段定义。
@Getter
@Document(GROUP_COLLECTION)
@TypeAlias(GROUP_COLLECTION)
@NoArgsConstructor(access = PRIVATE)
public class Group extends AggregateRoot {
private String name;//名称
private String appId;//所在的app
private List<String> managers;//管理员
private List<String> members;//普通成员
private boolean archived;//是否归档
private String customId;//自定义编号
private boolean active;//是否启用
private String departmentId;//由哪个部门同步而来
//...此处省略了Group的行为方法
}聚合根基本原则
产品代码都给你看了,可别再说不会DDD(六):聚合根与资源库
从上面的代码可以看出,聚合根只是普通的Java对象而已,真正使之称为聚合根的是一些特定的设计原则。
内聚性原则
对于Group例子,管理员managers、普通成员members以及启用标志active均是Group不可分割的属性,这些属性独立与Group是无法存在的。
对外黑盒原则
聚合根的外部不需要关心聚合根内部的实现细节,而只需要通过调用聚合根向外界暴露的共有的业务方法即可。具体表现为,外部对聚合根的调用只能通过根对象完成,而不能调用聚合根内部对象上的方法。举个例子:管理员可以向分组Group中添加成员 。
在Group类里面定义了一个addMember的方法。
@Getter
@Document(GROUP_COLLECTION)
@TypeAlias(GROUP_COLLECTION)
@NoArgsConstructor(access = PRIVATE)
public class Group extends AggregateRoot {
private String name; //名称
private String appId; //所在的app
private List < String > managers; //管理员
private List < String > members; //普通成员
private boolean archived; //是否归档
private String customId; //自定义编号
private boolean active; //是否启用
private String departmentId; //由哪个部门同步而来
//...此处省略了Group的行为方法
public void addMembers(List < String > memberIds, User user) {
if (isSynced()) {
throw new MryException(GROUP_SYNCED, "无法添加成员,已设置从部门同步。", "groupId", this.getId());
}
this.members = concat(members.stream(), memberIds.stream()).distinct().collect(toImmutableList());
addOpsLog("设置成员", user);
}
}还有一种就是通过外面实现,就是通过在service里面定义addGroupMember方法来实现,但是这样存在一些问题:
- 外部需要了解Group的内部结构,背离了对外黑盒的原则,本例中,外部通过group.getMember()获取到Group内部的member属性
- 聚合根内部的业务逻辑泄漏到外部,背离了内聚性原则,本例中,对group.isSynced()的调用原本应该放到Group中,结果却由外部承担了该职责。
在对外黑盒原则的指导下,聚合根自然形成了一个边界,它站在这个边界上向外声明:“我所包围的内部所有均由我负责,如果想访问我的内部,是禁止的,只能通过我这个根来访问。”
不变条件原则
不变条件,表示聚合根需要保证其内部在任何时候均处于一种合法的状态(即数据一致性需要得到保证),一个常见的例子就是,订单Order中有订单项OrderItem和订单价格Price,当订单项发生变化时,其价格也要随之发生变化,并且这两种变化应该在订单的同一个业务方法中完成。这一点很好理解,既然聚合根对外是一个黑盒,那么外界就不会负责给聚合根擦屁股,你聚合根需要自己保证自身的正确性。
比如:
应用管理员可以向分组Group中添加分组管理员,也就意味着分组管理员也是分组成员,那么在添加分组管理员的同时需要一并将其添加到分组成员中。
我们需要在聚合根内部保证不变条件不被破坏,因为不变条件往往意味着核心的业务逻辑。
通过ID引用其他聚合根原则
当一个聚合根需要引用另一个聚合根时,并不需要维持对另一个聚合根的整体引用,而只需要通过ID进行引用即可。出发点:聚合根和聚合根之间是一种平级关系,并不是隶属关系,每一个聚合根本身是一个相对独立的模块,其与其他聚合根的关系应该通过ID这种松耦合的方式进行引用,如果整体引用则更像是一种包含关系。
比如下面的appId, customId,而在managers,members字段中,则是以memberId引用相应成员。
@Getter
@Document(GROUP_COLLECTION)
@TypeAlias(GROUP_COLLECTION)
@NoArgsConstructor(access = PRIVATE)
public class Group extends AggregateRoot {
private String name;//名称
private String appId;//所在的app
private List<String> managers;//管理员
private List<String> members;//普通成员
private boolean archived;//是否归档
private String customId;//自定义编号
private boolean active;//是否启用
private String departmentId;//由哪个部门同步而来
//...省略其他代码
}与基础设施无关原则
既然整个领域模型与基础设施无关,那么 位于领域模型之内的聚合根自然也不能与基础设施相关,这样的好处是将业务复杂度与技术复杂度解藕开来,让业务模型可以独立于技术设施而完成自身的演变。
比如,假设一个项目需要从Spring框架迁移到Guice框架,此时如果能够保证领域模型与基础设施的无关性,那么对领域模型的迁移就变的非常简单了,基本上无需修改任何代码直接拷贝到新的项目即可。
跨聚合根用例
通常来讲,一个业务只会操作一个聚合根,但有时,一个业务用例可能会导致多个聚合根对象的更新,有两种情况:
1 如果聚合根在不同的进程空间中,那么解决方式一是通过使用事件驱动架构EDA,二是通过全局事物,比如JTA完成,基于全局事物的性能和效率低下等问题,DDD社区一般建议采用事件驱动架构,即在一个进程空间中只对其包含的聚合根进行操作,然后通过向其他进程空间发送事件通知的方式,使其他进程空间做相应的聚合根更新
2 如果聚合根在同一进程空间,那么最简单的就是直接同时更新多个聚合根,因为处于同一个本地事物中。
资源库
资源库以聚合根为单位完成对数据库的访问。也就是只有聚合根才拥有资源库,其他对象是没有对应的资源库,这也是资源库和DAO最大的区别。
在编码实现时,资源库方法所接受的参数和返回的数据都应该是聚合根对象。
(那如何区分聚合根,因为只有聚合根才有资源库,那没有资源库的非聚合根怎么保存?)
现状:新的业务需求,先想到如何建表,然后在编写业务代码。
在DDD中,这是一种反模式,既然是”领域驱动“,那么首先关心的是如恶化业务建模,而不是数据库建模。《整洁架构》中写道,数据库知识一个实现细节而已,不应该成为软件建模的主体。
(那么问题又来了,现在数据库就是业务模型,如何先考虑业务建模?)
资源库的作用,就是在业务复杂度和技术复杂度之间做了一层很好的隔离,让我门可以独立的看待软件的业务模型而不受技术设施的影响。从本质上讲,资源库做的事情知识实现了数据在内存和磁盘之间的相互传输而已。
在资源库中,重要的方法有三个:
- Group byId(String id)
- void save(Group group)
- void delete(Group group)
除了这些,还有些实现业务逻辑的查询,并不是为了前段显示的那种纯粹的查询,这种查询可以作为一个单独的关注点通过CQRS解决。
在DDD项目中,通常将资源库分为接口和实现类,将接口放在领域模型Domain中,而将实现类放在基础设施Infrastructur包中,这样的好处有两点:
1 通过依赖反转,使得领域模型不依赖于基础设施(阿?)
2 实现资源库的可插拔性,比如未来需要从MongoDB迁移到MySql,那么只需要创建新的实现类即可。
总结:
聚合根的设计原则及实现,其中包含内聚原则、对外黑盒原则和不变条件原则。
资源库与聚合根的关系。
七、实体与值对象
聚合根本身是一种实体Entity,下面将讲述实体以及相对立的值对象Value Object。
在对聚合根的学习中,我们知道两种类型对象,一种是具有生命周期的对象(比如成员Member),另外一种是只起描述作用的对象(比如地址Address),前者称为实体,后者称为值对象。
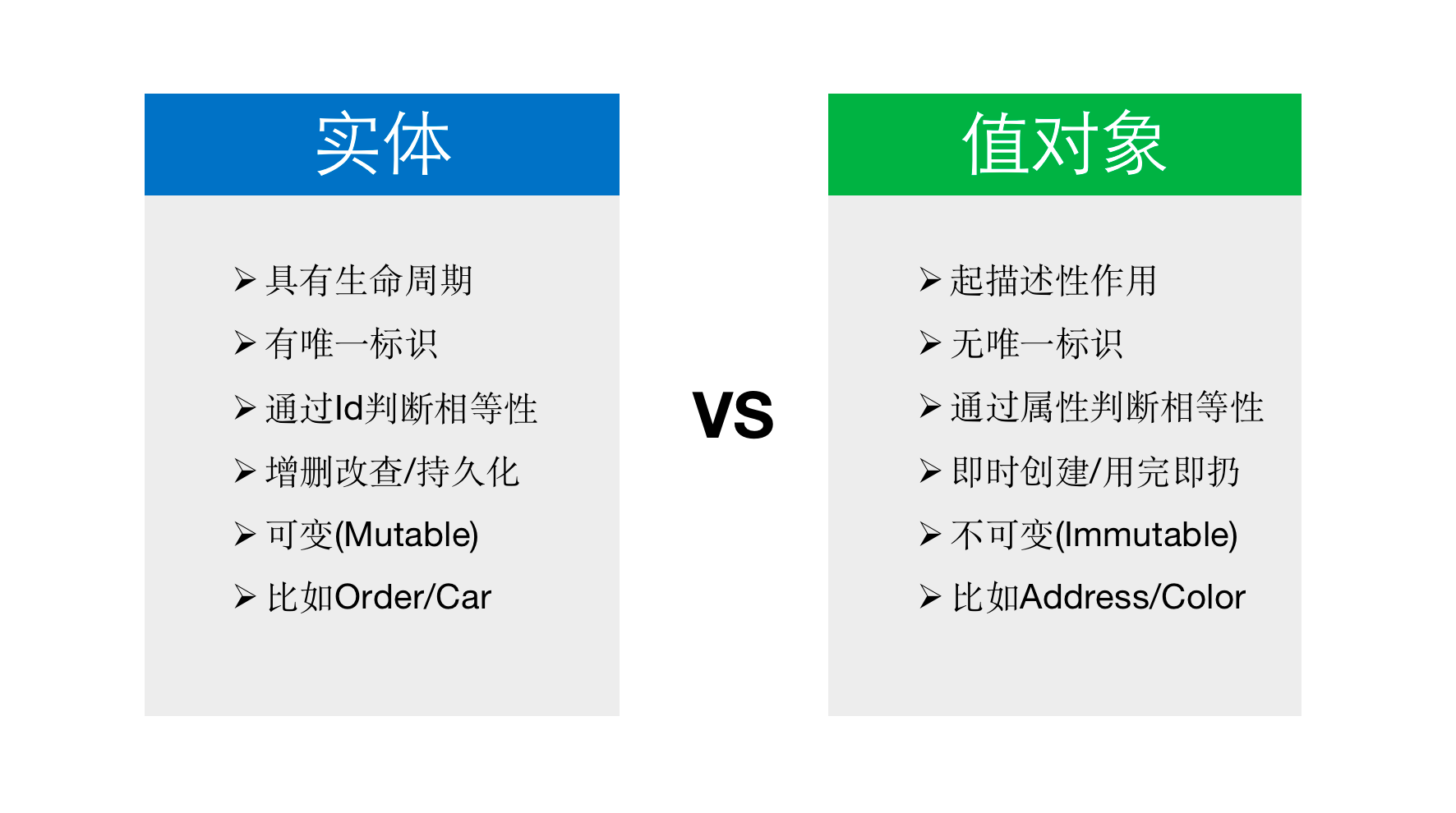
我们希望达到的目的是,将尽量多的概念建模为值对象,因为值对象比实体更加简单。
看个例子:
值对象Address:
简单的java类,不继承聚合根基类。
//Address
@Value
@Builder
@AllArgsConstructor(access = PRIVATE)
public class Address {
private final String province; //省份
private final String city; //城市
private final String district; //区县
private final String address; //详细地址
//......此处省略更多代码
}聚合根实体对象Member:
//Member
@Getter
@Document(MEMBER_COLLECTION)
@TypeAlias(MEMBER_COLLECTION)
@NoArgsConstructor(access = PRIVATE)
public class Member extends AggregateRoot {
private String name;//名字
private Role role;//角色
private String mobile;//手机号
private String email;//邮箱
private IdentityCard identityCard;//身份证
//...此处省略更多代码
}感觉实体和值对象没有什么区别,但是在唯一标识、相等性和可变性上存在很大区别。
唯一标识
值对象的“描述性作用”也意味着它无需唯一标识(即ID)即可完成使命,而实体恰恰相反,值对象Address没有ID,而实体Member的唯一标识存在于父类AggregateRoot的id字段中。
UUID的无序性在大数据量场景下可能存在性能问题,更偏向使用雪花算法。有些技术框架可以设置延后对ID的生成,例如Hibernate和数据库自增ID,强烈建议不要采用这些方式,因为这些方式所创建出来的实体直到保存到数据库的最后一刻都是非法的,更好的方式是在新建实体时即为之设置ID。
Changelog
4c155-on